Pika Blackwidow 引擎数据存储格式
Blackwidow本质上是基于rocksdb的封装,使本身只支持kv存储的rocksdb能够支持多种数据结构, 目前Blackwidow支持五种数据结构的存储:String结构(实际上就是存储key, value), Hash结构,List结构,Set结构和ZSet结构, 因为Rocksdb的存储方式只有kv一种, 所以上述五种数据结构最终都要落盘到Rocksdb的kv存储方式上,下面我们展示Blackwidow和rocksdb的关系并且说明我们是如何用kv来模拟多数据结构的。
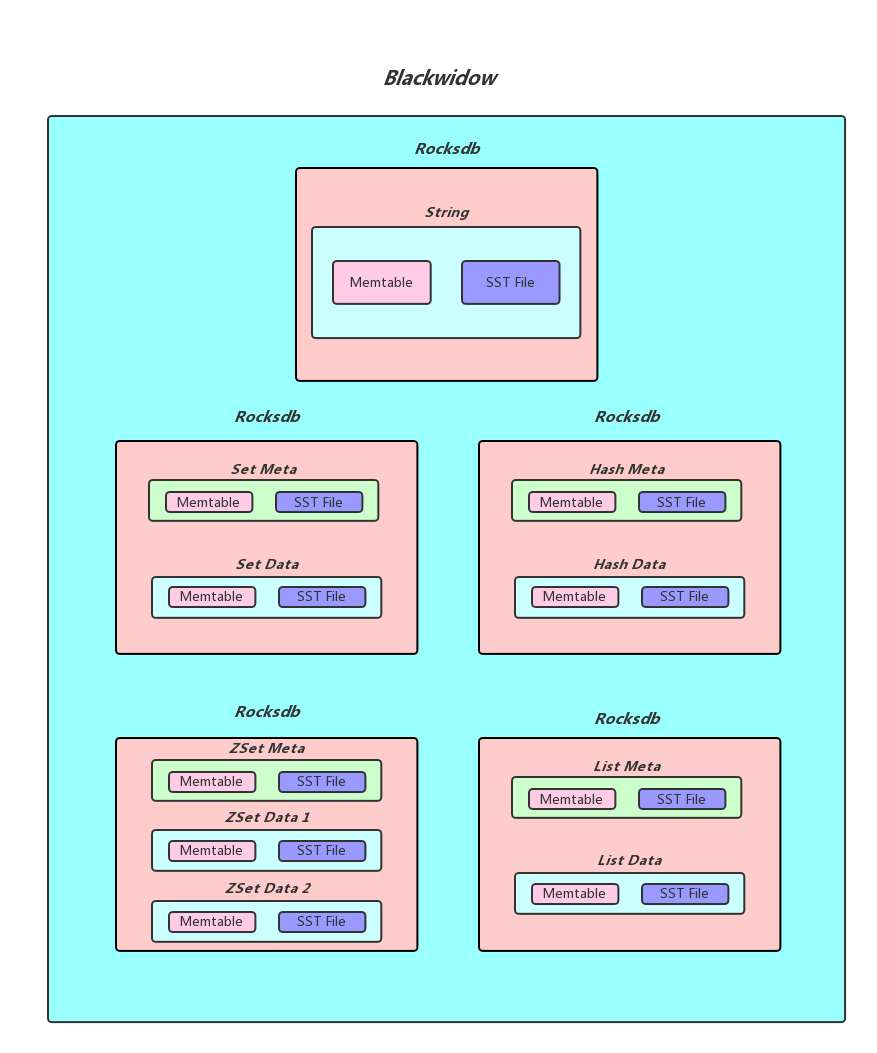
1. String结构的存储
String本质上就是Key, Value, 我们知道Rocksdb本身就是支持kv存储的, 我们为了实现Redis中的expire功能,所以在value后面添加了4 Bytes用于存储timestamp, 作为最后Rocksdb落盘的kv格式,下面是具体的实现方式:

如果我们没有对该String对象设置超时时间,则timestamp存储的值就是默认值0, 否则就是该对象过期时间的时间戳, 每次我们获取一个String对象的时候, 首先会解析Value部分的后四字节, 获取到timestamp做出判断之后再返回结果。
2. Hash结构的存储
blackwidow中的hash表由两部分构成,元数据(meta_key, meta_value), 和普通数据(data_key, data_value), 元数据中存储的主要是hash表的一些信息, 比如说当前hash表的域的数量以及当前hash表的版本号和过期时间(用做秒删功能), 而普通数据主要就是指的同一个hash表中一一对应的field和value,作为具体最后Rocksdb落盘的kv格式,下面是具体的实现方式:
- 每个hash表的meta_key和meta_value的落盘方式:

meta_key实际上就是hash表的key, 而meta_value由三个部分构成: 4Bytes的Hash size(用于存储当前hash表的大小) + 4Bytes的Version(用于秒删功能) + 4Bytes的Timestamp(用于记录我们给这个Hash表设置的超时时间的时间戳, 默认为0)
- hash表中data_key和data_value的落盘方式:

data_key由四个部分构成: 4Bytes的Key size(用于记录后面追加的key的长度,便与解析) + key的内容 + 4Bytes的Version + Field的内容, 而data_value就是hash表某个field对应的value。
- 如果我们需要查找一个hash表中的某一个field对应的value, 我们首先会获取到meta_value解析出其中的timestamp判断这个hash表是否过期, 如果没有过期, 我们可以拿到其中的version, 然后我们使用key, version,和field拼出data_key, 进而找到对应的data_value(如果存在的话)
3. List结构的存储
blackwidow中的list由两部分构成,元数据(meta_key, meta_value), 和普通数据(data_key, data_value), 元数据中存储的主要是list链表的一些信息, 比如说当前list链表结点的的数量以及当前list链表的版本号和过期时间(用做秒删功能), 还有当前list链表的左右边界(由于nemo实现的链表结构被吐槽lrange效率低下,所以这次blackwidow我们底层用数组来模拟链表,这样lrange速度会大大提升,因为结点存储都是有序的), 普通数据实际上就是指的list中每一个结点中的数据,作为具体最后Rocksdb落盘的kv格式,下面是具体的实现方式
- 每个list链表的meta_key和meta_value的落盘方式:

meta_key实际上就是list链表的key, 而meta_value由五个部分构成: 8Bytes的List size(用于存储当前链表中总共有多少个结点) + 4Bytes的Version(用于秒删功能) + 4Bytes的Timestamp(用于记录我们给这个List链表设置的超时时间的时间戳, 默认为0) + 8Bytes的Left Index(数组的左边界) + 8Bytes的Right Index(数组的右边界)
- list链表中data_key和data_value的落盘方式:

data_key由四个部分构成: 4Bytes的Key size(用于记录后面追加的key的长度,便与解析) + key的内容 + 4Bytes的Version + 8Bytes的Index(这个记录的就是当前结点的在这个list链表中的索引), 而data_value就是list链表该node中存储的值
4. Set结构的存储
blackwidow中的set由两部分构成,元数据(meta_key, meta_value), 和普通数据(data_key, data_value), 元数据中存储的主要是set集合的一些信息, 比如说当前set集合member的数量以及当前set集合的版本号和过期时间(用做秒删功能), 普通数据实际上就是指的set集合中的member,作为具体最后Rocksdb落盘的kv格式,下面是具体的实现方式:
- 每个set集合的meta_key和meta_value的落盘方式:

meta_key实际上就是set集合的key, 而meta_value由三个部分构成: 4Bytes的Set size(用于存储当前Set集合的大小) + 4Bytes的Version(用于秒删功能) + 4Bytes的Timestamp(用于记录我们给这个set集合设置的超时时间的时间戳, 默认为0)
- set集合中data_key和data_value的落盘方式:

data_key由四个部分构成: 4Bytes的Key size(用于记录后面追加的key的长度,便与解析) + key的内容 + 4Bytes的Version + member的内容, 由于set集合只需要存储member, 所以data_value实际上就是空串
5. ZSet结构的存储
blackwidow中的zset由两部部分构成,元数据(meta_key, meta_value), 和普通数据(data_key, data_value), 元数据中存储的主要是zset集合的一些信息, 比如说当前zset集合member的数量以及当前zset集合的版本号和过期时间(用做秒删功能), 而普通数据就是指的zset中每个member以及对应的score, 由于zset这种数据结构比较特殊,需要按照memer进行排序,也需要按照score进行排序, 所以我们对于每一个zset我们会按照不同的格式存储两份普通数据, 在这里我们称为member to score和score to member,作为具体最后Rocksdb落盘的kv格式,下面是具体的实现方式:
- 每个zset集合的meta_key和meta_value的落盘方式:

meta_key实际上就是zset集合的key, 而meta_value由三个部分构成: 4Bytes的ZSet size(用于存储当前zSet集合的大小) + 4Bytes的Version(用于秒删功能) + 4Bytes的Timestamp(用于记录我们给这个Zset集合设置的超时时间的时间戳, 默认为0)
- 每个zset集合的data_key和data_value的落盘方式(member to score):

member to socre的data_key由四个部分构成:4Bytes的Key size(用于记录后面追加的key的长度,便与解析) + key的内容 + 4Bytes的Version + member的内容, data_value中存储的其member对应的score的值,大小为8个字节,由于rocksdb默认是按照字典序进行排列的,所以同一个zset中不同的member就是按照member的字典序来排列的(同一个zset的key size, key, 以及version,也就是前缀都是一致的,不同的只有末端的member).
- 每个zset集合的data_key和data_value的落盘方式(score to member):

score to member的data_key由五个部分构成:4Bytes的Key size(用于记录后面追加的key的长度,便与解析) + key的内容 + 4Bytes的Version + 8Bytes的Score + member的内容, 由于score和member都已经放在data_key中进行存储了所以data_value就是一个空串,无需存储其他内容了,对于score to member中的data_key我们自己实现了rocksdb的comparator,同一个zset中score to member的data_key会首先按照score来排序, 在score相同的情况下再按照member来排序
Blackwidow相对于Nemo有哪些优势
- Blackwidow采用了rocksdb的column families的新特性,将元数据和实际数据分开存放(对应于上面的meta数据和data数据), 这种存储方式相对于Nemo将meta, data混在一起存放更加合理, 并且可以提升查找效率(比如info keyspace的效率会大大提升)
- Blackwidow中参数传递大量采用Slice而Nemo中采用的是std::string, 所以Nemo会有很多没有必要的string对象的构造函数以及析构函数的调用,造成额外的资源消耗,而Blackwidow则不会有这个问题
- Blackwidow对kv模拟多数据结构的存储格式上做了重新设计(具体可以参考Nemo引擎数据存储格式和本篇文章),使之前在Nemo上出现的一些无法解决的性能问题得以解决,所以Blackwidow的多数据结构在某些场景下性能远远优于Nemo
- 原来Nemo对多数据结构的Key的长度最大只能支持到256 Bytes,而Blackwidow经过重新设计,放开了多数据结构Key长度的这个限制
- Blackwidow相对于Nemo更加节省空间,Nemo由于需要nemo-rocksdb的支持,所以不管在meta还是data数据部分都追加了version和timestamp这些信息,并且为了区分meta_key和data_key, 在最前面加入s和S(拿Set数据结构打比方),Blackwidow在这方面做了优化,使同样的数据量下Blackwidow所占用的空间比Nemo要小(举个例子,Blackwidow中List结构中的一个Node就比Nemo中的一个Node节省了16 Bytes的空间)
- Blackwidow在锁的实现上参照了RocksDB事务里锁的实现方法,而弃用了之前Nemo的行锁,所以在多线程对同一把锁有抢占的情况下性能会有所提升